StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks (논문 리뷰)
안녕하세요.
딥러닝 스터디에서 GAN의 응용을 소개하게 된 hyenzzang입니다.

제가 이번에 소개할 논문은 StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 입니다. (Paper)
StackGAN은 Text to Image에 활용할 수 있는 모델입니다.
Text to Image는 어떤 문장이 주어졌을 때 그 내용을 전부 반영해서 이미지를 생성하는 모델이죠.
기존의 Vanilla GAN으로도, Text to Image를 할 수는 있지만 고화질의 이미지를 생성해내는 것은 힘듭니다.

위 사진의 마지막 행이 Vanilla GAN이 생성한 이미지인데 저화질이며 객체를 명확히 알아보기가 힘듭니다.
따라서 2개의 GAN을 Stack 하여, Text to high resolution image 라는 하나의 Task를
Text to low resolution image와 low resolution image to high resolution image 이라는 두 단계로 쪼개는 것이
StackGAN의 핵심 아이디어입니다.

StackGAN을 알아보기 전에 GAN에 대해 한번 짚고 가면,
GAN은 Generator와 Discriminator의 적대적 관계를 통해 이미지를 생성하는 방법입니다.
Generator는 Discriminator가 판별하기 더욱 어렵고 진짜 같은 이미지가 생성되는 방향으로 학습이 되고
반대로 Discrimininator는 이미지가 진짜인지 가짜인지 더 잘 판별할 수 있도록 학습 됩니다.
이러한 적대적 관계를 통해 Generator의 성능을 높이는 것이 GAN의 목적이죠.
StackGAN은 GAN에 "Condition"이 추가되는 Conditional GAN (CGAN)을 기반으로 합니다.
Conditional GAN?
예를 들어 우리가 MNIST와 같은 손글씨 숫자 데이터로 GAN을 학습한다고 생각해 봅시다!
Test시에 결국 어떤 숫자가 생성되게 될 텐데, 0부터 9 중에 어떤 숫자가 출력될지는 미지수입니다.
따라서 3과 같은 특정한 숫자를 원할 때, 이 label을 CGAN의 condition으로 넣어줌으로써 label에 따른 이미지가 생성되도록 하는 방법입니다.

이제 다시 StackGAN으로 돌아왔습니다.
StackGAN의 전체 구조는 위 사진과 같고 크게 세 가지로 나눌 수 있습니다.
- Conditioning Augmentation (초록색)
- Stage-I GAN: Text to low resolution image (파란색)
- Stage-II GAN: Text conditional low-resolution image to high resolution image (분홍색)
Conditioning Augmentation

가장 먼저 이미지 생성을 원하는 문장 (Text description) t를 입력값으로 받으면,
Pre-trained 된 인코더를 통해서 텍스트를 어떤 차원으로 임베딩 합니다.
Text-to-Image Task를 하기 위해서는 텍스트와 이미지가 Pair한 학습 데이터로 이루어져 있어야 하는데,
임베딩 공간이 100차원 이상이기 때문에 (image, text) 쌍의 양이 충분히 많지 않을 때는 임베딩 공간에서 불연속성이 나타나고,
올바른 학습을 하기가 어렵습니다.
이러한 문제를 해결하기 위해 Conditioning Augmentation 방법을 활용할 수 있습니다.
생성된 임베딩 벡터 pi를 Fully connected layer에 통과시켜 128차원의 mu_0와 sigma_0을 뽑아내고,
표준 정규 분포로부터 128차원의 epsilon을 샘플링 합니다.
그리고 이 epsilon을 sigma_0와 element wise product하고 mu_0을 element wise sum 함으로써
conditioning 정규 분포 샘플링 벡터 c0_hat 를 생성하는 것입니다.

이러한 Conditioning Augmentation은 모델의 robustness를 높입니다.
Stage-I GAN

Stage-I GAN에서는 Conditioning Augmentation으로 생성된
c0_hat을 입력값으로 받아서 저화질의 이미지를 생성합니다.
먼저 c0_hat을 표준 정규 분포를 따르는 노이즈 z를 concatenate하고
Deconvolutional layer를 통해 Upsampling하여 64 x 64 x 3의 저화질 Fake 이미지를 생성합니다.
본 논문에 Upsampling과 Downsampling에 대한 구체적인 구조는 나와있지 않으나 저자의 Github를 통해 구조를 확인할 수 있습니다.
Discriminator는 Generator가 생성한 Fake 이미지와 Real 이미지를 입력값으로 받아 Downsampling을 거칩니다.
이를 통해 64 x 64 x 3 이미지를 4 x 4 x 512 차원으로 만들고
이를 4 x 4 x 128 임베딩 벡터 pi와 Concatenate 합니다.
최종적으로 이 벡터를 convolution 함으로써 0-1 사이의 값을 출력하게 됩니다.
Stage-II GAN

Stage-II GAN은 저해상도 이미지로부터 고해상도 이미지를 생성하는 역할을 합니다.
Stage-I GAN을 통해 생성된 이미지와 임베딩 벡터 pi를 입력값으로 받습니다.
임베딩 벡터 pi는 Stage-II GAN에서 다시 한번 Conditioning Augmentation을 거쳐 벡터 c_hat을 샘플링합니다.
이 부분에서는 저해상도 이미지로부터 고해상도 이미지를 생성하기 위해 Encoder-Decoder 구조를 사용합니다.
먼저 64 x 64 x 3 이미지를 Downsampling해서 16 x 16 x 512의 벡터로 변환합니다.
그리고 벡터 c_hat을 concatenate 해서 residual block에 입력합니다.

Residual Block?
Residual connection은 몇 개의 레이어를 건너 뛰어서
데이터가 신경망 구조의 후반부에 또 다른 경로로 잘 도달할 수 있도록 입력값을 출력에 더해주는 방법으로,
긴 네트워크 구조에서 Gradient가 잘 전달될 수 있도록 하기 위해 도입되었습니다.
Residual Block을 통과한 다음, Upsampling을 통해 256 x 256 x 3의 고화질 이미지를 생성하게 되고
Fake 이미지와 Real 이미지를 입력값으로 받아 다시 한 번 Downsampling 을 지난 후, 임베딩 벡터 pi를 concatenate 합니다.
concatenate된 벡터 shape은 Stage-I과 동일한 4 x 4 x 640이며
Discriminator는 최종적으로 convolution을 통해 0에서 1사이의 scalar value를 출력합니다.
Loss

Stage-I과 II의 Loss는 큰 차이가 없습니다.
먼저 Stage-I GAN의 Discriminator에는 입력값이 (이미지, 텍스트) 쌍으로 들어가게 되는데
쌍의 조합에는 총 세가지가 있습니다.
- 진짜 이미지와 그에 알맞은 텍스트가 들어가는 경우: 1점
- 텍스트에 맞지않은 이미지와 텍스트가 들어가는 경우: 0점
- Generator가 만든 가짜 이미지와 텍스트가 들어가는 경우: 0점
첫번째 경우에 대해서는 1에 가깝게,
나머지 두 경우에 대해서는 0에 가깝게 판별 함으로써 Loss 값을 최대화하는 것이 Discriminator의 역할이 되겠습니다.
그리고 Generator는 본인이 생성한 이미지에 대해 Discriminator가 판단한 값이 1에 가깝게 판별 되기를 바라야겠죠.
Generator는 Loss의 값이 최소화 하는 것을 목표로 합니다.
Generator Loss에는 두 확률 분포의 차이를 계산하는 데에 사용되는 KL Divergence가 포함 되는데요.
이거는 Conditional Augmentation 단계에서 추정한 mu와 sigma를 바탕으로 만든 Conditioning 정규 분포가
표준 정규분포와 유사한 분포를 나타내도록 학습하게 되면 모델이 더 안정적일 수 있기에 포함된 부분입니다. (lambda = 1)
Stage-II GAN에서는
Discriminator의 이미지가 64 x 64에서 256 x 256으로 바뀌는 것,
그리고 Generator의 입력값이 Noise 벡터가 아닌, 저해상도 이미지로 바뀌는 것을 제외하곤 loss 계산이 동일합니다.
Experiments
- Dataset
- CUB
- Oxford-102
- MS COCO
- Evaluation Metrics
- Inception Score
- Human Ranking
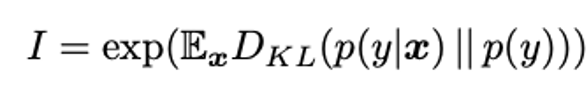
본 논문에서는 기존의 SOTA 모델인 GAN-INT-CLS, GAWWN 과의
정량적, 정성적 비교를 통해 StackGAN의 성능을 보여주었습니다.
정량적 성능 측정을 위해서는 Inception Score를 사용하였는데요,
이 지표는 이미지의 품질과 다양성 측면을 평가할 수 있고
이미지의 품질이 높다고 측정되기 위해서는 각 이미지 샘플 x에 대해 label y의 예측 가능성이 높아야 합니다.
또한, 이미지 다양성 측면이 높게 평가되기 위해서는 label y 의 분포가 균일해야 합니다.
두 기준을 KL Divergence를 활용하여 하나의 식으로 표현할 수 있으며,
생성된 이미지에서 y를 예측하기 위해서는 pre-trained incpetion network를 사용할 수 있습니다.
정성적 평가를 위해서는 10명을 대상으로 Human Ranking 기법을 수행했다고 합니다.
Results

결과는 다음과 같습니다.
StackGAN은 세가지 데이터셋에 대해, 두 가지 Metric에 대해 모두 가장 성능이 높게 평가 되었습니다.
생성된 사진을 확인해보면 어떨까요?

CUB 데이터셋의 결과는 다음과 같습니다.
어떤 모델이 가장 고품질인 것 같나요?

Oxford와 COCO 데이터셋에 대한 결과입니다.

덧붙여 StackGAN이 등장한지 어느덧 5년이 지났습니다.
이후 StackGAN++이라는 한 단계 더 발전된 모델이 등장했고, 더욱 자연스러운 고화질 이미지를 생성하는 결과를 나타냈습니다.
최근에는 DALL-E, Novel AI 등 성능이 매우 좋은 Text-to-Image 모델이 등장했는데요.
현재의 이미지 제너레이터 모델과는 당연히 비교 불가이지만...
StackGAN은 기존까지 구현이 어려웠던,
텍스트로부터 마치 실제 사진 같은 고화질 이미지 생성을 실현했다는 점에서 의의가 있다고 생각합니다.
이상으로 StackGAN에 대한 설명을 마치도록 하겠습니다.
감사합니다!
Reference
https://arxiv.org/abs/1612.03242
https://medium.com/humanscape-tech/paper-review-stackgan-6e6605be6ae9
https://indico.cern.ch/event/996876/contributions/4188445/attachments/2176630/3675575/stackgan.pdf